
<로또 최신 회차까지 데이터 가져오기>




#url 가져올 때 메인창에서 검색을 해야하는 이유
: 어떤 키워드를 검색하고 메인 창이 아닌 창에서 연속으로 다른 키워드를 검색할 경우, url에 기록 남음.
깔끔한 url 을 가져오기 위해 메인 창에서 검색해야 함.
#로또 현재 회차 데이터 가져오기
>import requests
>from bs4 import BeautifulSoup
>import pandas as pd
>
>
>url=requests.get("https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EB%A1%9C%EB%98%90")
>html=BeautifulSoup(url.text) #text로 번역
>html.select('a._lotto-btn-current')[0] #문자열이 아닌 html상태로 가져오기
<a class="_lotto-btn-current" href="#" nocr=""><em>972회</em>차 당첨번호 <span>2021.07.17</span></a>
a라는 태그에서 class속성 값이 lotto-bnt-current 인 곳에 현재 회차 데이터가 다른 데이터들과 함께 있음.

그 중에서 <em> </em>에 해당하는 부분에 내가 가져오고 싶은 회차 데이터가 있음.
#회차 정보만 가져오기
>html.select('a._lotto-btn-current')[0].select('em')
[<em>972회</em>]
#회차의 숫자만 가져오기
>html.select('a._lotto-btn-current')[0].select('em')[0].text
'972회'
#'회'를 빈칸으로 만들기
>html.select('a._lotto-btn-current')[0].select('em')[0].text.replace('회','')
'972'
#current 라는 변수에 문자열로 되어있는 회차를 정수형으로 저장하기
>current=int(html.select('a._lotto-btn-current')[0].select('em')[0].text.replace('회',''))
>current
972#전체 코드
>import requests
>from bs4 import BeautifulSoup
>import pandas as pd
>
>
>total=[]
>
>url=requests.get("https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EB%A1%9C%EB%98%90")
>html=BeautifulSoup(url.text)
>current=int(html.select('a._lotto-btn-current')[0].select('em')[0].text.replace('회','')) #회를 빈칸으로 만들기
>
>for n in range(1,101):
>
> url=requests.get(f"https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EB%A1%9C%EB%98%90+{n}%ED%9A%8C")
> html=BeautifulSoup(url.text)
>
> lotto_number=html.select('div.num_box')[0].select('span')
> del lotto_number[6]
>
> box=[]
>
> for i in lotto_number:
> box.append(int(i.text))
>
> total.append(box)
>
> print('로또 {}회차 데이터 저장완료 : {}'.format(n,box))#결과
로또 1회차 데이터 저장완료 : [10, 23, 29, 33, 37, 40, 16]
로또 2회차 데이터 저장완료 : [9, 13, 21, 25, 32, 42, 2]
로또 3회차 데이터 저장완료 : [11, 16, 19, 21, 27, 31, 30]
로또 4회차 데이터 저장완료 : [14, 27, 30, 31, 40, 42, 2]
로또 5회차 데이터 저장완료 : [16, 24, 29, 40, 41, 42, 3]
로또 6회차 데이터 저장완료 : [14, 15, 26, 27, 40, 42, 34]
..........생략.............
로또 94회차 데이터 저장완료 : [5, 32, 34, 40, 41, 45, 6]
로또 95회차 데이터 저장완료 : [8, 17, 27, 31, 34, 43, 14]
로또 96회차 데이터 저장완료 : [1, 3, 8, 21, 22, 31, 20]
로또 97회차 데이터 저장완료 : [6, 7, 14, 15, 20, 36, 3]
로또 98회차 데이터 저장완료 : [6, 9, 16, 23, 24, 32, 43]
로또 99회차 데이터 저장완료 : [1, 3, 10, 27, 29, 37, 11]
로또 100회차 데이터 저장완료 : [1, 7, 11, 23, 37, 42, 6]
<같은 방법으로 연금복권 데이터 크롤링>


>import requests
>from bs4 import BeautifulSoup
>import pandas as pd
>
>
>url=requests.get("https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%97%B0%EA%B8%88%EB%B3%B5%EA%B6%8C")
>html=BeautifulSoup(url.text)
>current=int(html.select('a._lottery-btn-current')[0].select('em')[0].text[:-1])
>
>total=[]
>
>for n in range(1,current+1):
> url=requests.get(f"https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%97%B0%EA%B8%88%EB%B3%B5%EA%B6%8C+{n}%ED%9A%8C")
> html=BeautifulSoup(url.text)
>
> box=[]
> for i in html.select("ul.win_num")[0].select('span'):
> box.append(i.text)
>
> total.append(box)
>
> print("{}회 연금복권 데이터 저장완료:{}".format(n,box))#설명
#현재 회차까지의 번호 데이터 가져오기
>url=requests.get("https://search.naver.com/search.naver? where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%97%B0%EA%B8%88%EB%B3%B5%EA%B6%8C")
>html=BeautifulSoup(url.text)
>current=int(html.select('a._lottery-btn-current')[0].select('em')[0].text[:-1])#현재 회차까지의 모든 데이터 문자열 형태로 가져와 html변수에 저장하기
for n in range(1,current+1):
url=requests.get(f"https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%97%B0%EA%B8%88%EB%B3%B5%EA%B6%8C+{n}%ED%9A%8C")
html=BeautifulSoup(url.text)#box 리스트에 번호 데이터 부분만 저장하고 total 리스트에 모두 저장하기
box=[]
for i in html.select("ul.win_num")[0].select('span'):
box.append(i.text)
total.append(box)#결과
1회 연금복권 데이터 저장완료:['4조', '1', '6', '2', '1', '3', '2']
2회 연금복권 데이터 저장완료:['2조', '4', '5', '0', '5', '5', '8']
3회 연금복권 데이터 저장완료:['4조', '5', '4', '4', '9', '5', '5']
4회 연금복권 데이터 저장완료:['4조', '1', '2', '4', '4', '2', '0']
.........생략..........
60회 연금복권 데이터 저장완료:['5조', '2', '1', '6', '5', '1', '0']
61회 연금복권 데이터 저장완료:['3조', '5', '7', '5', '8', '6', '2']
62회 연금복권 데이터 저장완료:['4조', '0', '1', '4', '0', '7', '3']
63회 연금복권 데이터 저장완료:['4조', '3', '3', '5', '2', '2', '6']
#숫자 데이터들만 저장하기
import requests
from bs4 import BeautifulSoup
import pandas as pd
url=requests.get("https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%97%B0%EA%B8%88%EB%B3%B5%EA%B6%8C")
html=BeautifulSoup(url.text)
current=int(html.select('a._lottery-btn-current')[0].select('em')[0].text[:-1])
total=[]
for n in range(1,current+1):
url=requests.get(f"https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%97%B0%EA%B8%88%EB%B3%B5%EA%B6%8C+{n}%ED%9A%8C")
html=BeautifulSoup(url.text)
box=[]
for i in html.select("ul.win_num")[0].select('span'):
box.append(int(i.text[0]))
total.append(box)
print("{}회 연금복권 데이터 저장완료:{}".format(n,box))#i.text 부분에서 0번째는 모두 숫자
문자열로 표현된 숫자를 int 형으로 변환
#결과
1회 연금복권 데이터 저장완료:[4, 1, 6, 2, 1, 3, 2]
2회 연금복권 데이터 저장완료:[2, 4, 5, 0, 5, 5, 8]
3회 연금복권 데이터 저장완료:[4, 5, 4, 4, 9, 5, 5]
4회 연금복권 데이터 저장완료:[4, 1, 2, 4, 4, 2, 0]
.....생략.........
60회 연금복권 데이터 저장완료:[5, 2, 1, 6, 5, 1, 0]
61회 연금복권 데이터 저장완료:[3, 5, 7, 5, 8, 6, 2]
62회 연금복권 데이터 저장완료:[4, 0, 1, 4, 0, 7, 3]
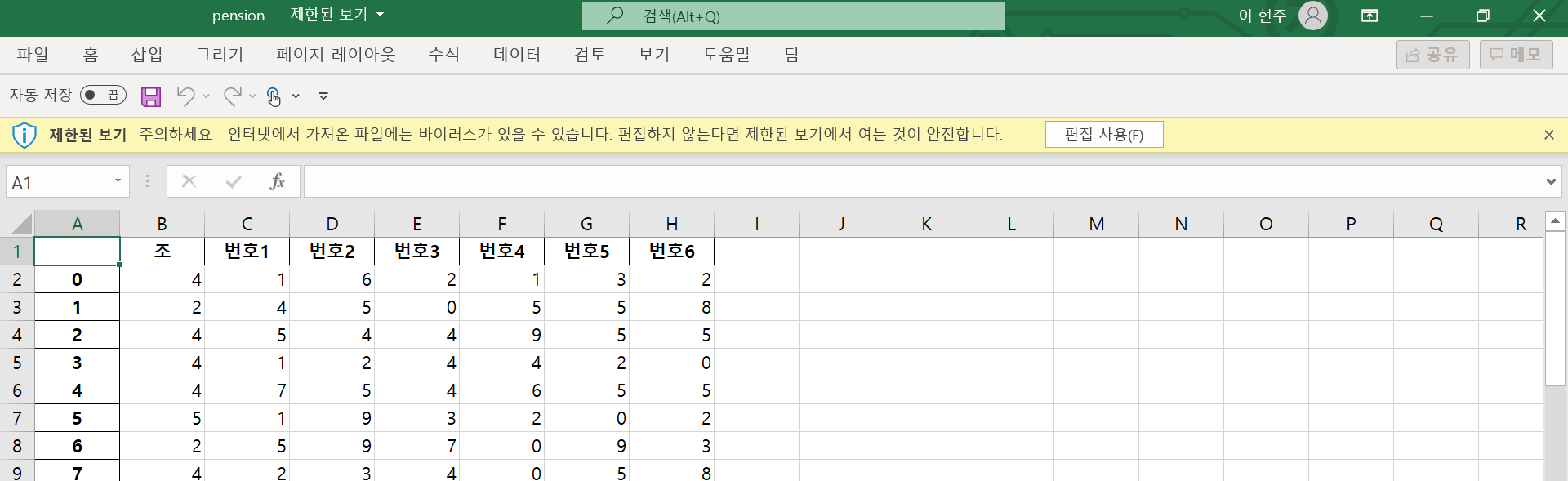
63회 연금복권 데이터 저장완료:[4, 3, 3, 5, 2, 2, 6]#표와 엑셀로 저장
df=pd.DataFrame(total,columns=['조','번호1','번호2','번호3','번호4','번호5','번호6'])
df.to_excel('pension.xlsx')
df
#'pension.xlsx' 이름의 엑셀 파일도 생성 됨.
반응형
'Python > 파이썬으로 배우는 머신러닝 기초 교육' 카테고리의 다른 글
| 3일차(데이터 가공) (0) | 2021.07.23 |
|---|---|
| 2일차(데이터 크롤링3) (0) | 2021.07.20 |
| 2일차(데이터 크롤링) (0) | 2021.07.15 |
| 2일차(파이썬 기초) (0) | 2021.07.15 |
| 1일차(파이썬 기초) (0) | 2021.07.07 |