3일차(데이터 분석 및 시각화)
#seaborn : 파이썬 시각화 라이브러리
#데이터 시각화가 필요한 이유 : 수치로 되어있는 데이터보다 별도의 분석 없이 빠르고 직관적인 이해가 가능
#seaborn라이브러리에 저장된 데이터 가져오기
import seaborn as sns
anscombe=sns.load_dataset("anscombe")
anscombe


##anscombe는 seaborn 라이브러리에 저장되어있는 데이터 집합
##anscombe외에 tips라는 데이터 집합도 있음.
#특정 열에 접근하기
anscombe[anscombe['dataset']=='I']

##ansscombe의 dataset열이 I인 값에만 접근
#데이터 저장하고 데이터별로 평균값 구하기
>data1=anscombe[anscombe['dataset']=='I']
>data2=anscombe[anscombe['dataset']=='II']
>data3=anscombe[anscombe['dataset']=='III']
>data4=anscombe[anscombe['dataset']=='IV']
>
>print(data1.mean())
>print(data2.mean())
>print(data3.mean())
>print(data4.mean())
x 9.000000
y 7.500909
dtype: float64
x 9.000000
y 7.500909
dtype: float64
x 9.0
y 7.5
dtype: float64
x 9.000000
y 7.500909
dtype: float64##평균값이 다 같은데 그럼 모두 같은 데이터일까??NO!
##데이터 시각화를 통해 다른 데이터라는 것을 시각적으로 알 수 있음.
#matplotlib라이브러리를 이용한 그래프 그리기
import matplotlib.pyplot as plt #그림 그려주는 라이브러리
fig=plt.figure() #그림 그리기 위한 도화지
ax1=fig.add_subplot(2,2,1)
ax2=fig.add_subplot(2,2,2)
ax3=fig.add_subplot(2,2,3)
ax4=fig.add_subplot(2,2,4)

#산점도 그리기
ax1.scatter(data1['x'],data1['y'])
ax2.scatter(data2['x'],data2['y'])
ax3.scatter(data3['x'],data3['y'])
ax4.scatter(data4['x'],data4['y'])
fig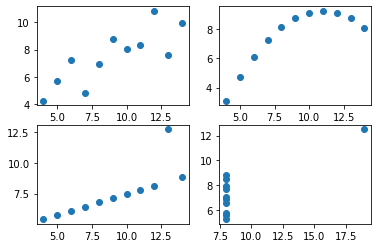
#데이터 별 제목 붙이기
ax1.set_title('Data1')
ax2.set_title('Data2')
ax3.set_title('Data3')
ax4.set_title('Data4')
fig

##제목 축이랑 겹침.
#전체 제목 붙이기
fig.suptitle('Ansxombe Data')
fig
#축과 제목이 겹치는 부분 제거하기
fig.tight_layout()
fig
##평균을 내면 모두 같은 값이 나오지만, 그래프로 확인해본 결과 모두 값이 다른 데이터라는 것을 알 수 있음.
#seaborn에 저장되어 있는 tips 데이터 가져오기
tips=sns.load_dataset('tips')
tips
#그래프를 그리기위한 틀 만들기
fig=plt.figure()
ax1=fig.add_subplot(1,1,1) #1행1열에 첫번째 자리 할당
#matplotlib를 이용하여 히스토그램 그리기
ax1.hist(tips['total_bill'],bins=20) #bins=20 >> 막대기를 20개 그리겠다.(커스터마이징 가능)
ax1.set_title('Histigram')
ax1.set_xlabel('Total Bill')
ax1.set_ylabel('Frequency')
fig
##matplotlib은 커스터마이징이 가능하고 seaborn은 알아서 그려주는 느낌..
#matplotlib이용하여 산점도 그리기
fig=plt.figure()
ax1=fig.add_subplot(1,1,1)
ax1.scatter(tips['total_bill'],tips['tip'])
#seaborn을 이용하여 히스토그램과 밀집도 그래프 그리기
ax=sns.distplot(tips['total_bill'])
ax.set_title('Histogram')
ax=sns.distplot(tips['total_bill'],kde=False) #kde는 밀집도 그래프 유무 결정
ax.set_title('Histogram')
##kde는 True/False로 밀집도 그래프 선의 유뮤를 결정함.
ax=sns.distplot(tips['total_bill'],rug=True) #데이터가 밀집된 곳에 작은 선 그리기
ax.set_title('Histogram')
##rug 는 데이터의 밀집도를 작은 선으로 나타냄.
tips
#seaborn을 이용하여 데이터 수 그래프로 나타내기
##countplot=막대그래프
ax=sns.countplot('day',data=tips)
ax.set_title('Count of Days')
ax.set_xlabel('Day of the Week')
ax.set_ylabel('Frequency')
##countplot 는 막대그래프 그려줌.
##regplot=산점도
sns.regplot(x='total_bill',y='tip',data=tips,fit_reg=False)
##fit_reg는 선의 유무 결정
##joinplot=산점도 그래프+히스토그램
sns.jointplot(x='total_bill',y='tip',data=tips)
sns.jointplot(x='total_bill',y='tip',data=tips,kind='hex')
##hex로 산점도를 육각형 그래프로 설정가능하며 데이터의 수가 많아질수록 색이 진해짐.
##barplot=막대그래프
sns.barplot(x='time',y='total_bill',data=tips)

##가운데 검은 선은 신뢰구간(95%)을 나태내며 설정이 가능함.
sns.barplot(x='time',y='total_bill',data=tips,ci=None)
##ci=None 으로 신뢰구간 없앨 수 있음.
##boxplot=상자그림
sns.boxplot(x='time',y='total_bill',data=tips)


##violinplot=마주본 밀도함수 그래프
sns.violinplot(x='time',y='total_bill',data=tips)

##pairplot:변수들끼리의 상관관계를 한눈에 볼 수 있는 그래프
sns.pairplot(tips) #그릴수 있는 모든 그림 그려줌

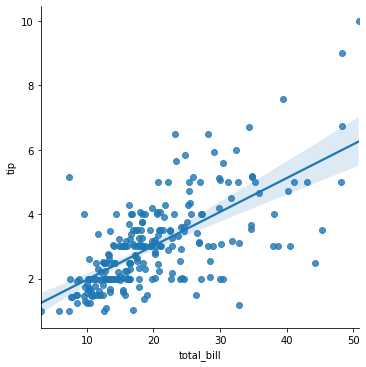
#implot=상관 관계와 선형회귀선 그래프
sns.lmplot(x='total_bill',y='tip',data=tips)
#여러가지 옵션 사용하기
sns.violinplot(x='time',y='total_bill',data=tips,hue='sex')
##hue='sex' 옵션을 통해 성별(Male,Female)을 구분하여 그래프를 생성
sns.violinplot(x='time',y='total_bill',data=tips,hue='sex',split=True)
##hue 옵션을 통해 성별을 나누고, split='True' 옵션으로 성별 마주보는 그래프 생성
sns.pairplot(tips,hue='sex')
##hue 옵션으로 성별에 따른 데이터 그래프 생성
sns.lmplot(x='total_bill',y='tip',data=tips,hue='day',fit_reg=False)
##fit_reg=False 옵션으로 회귀선 제거
sns.lmplot(x='x',y='y',data=anscombe,fit_reg=False,col='dataset')

##col='dataset' 옵션으로 dataset 값에 따른 상관관계 그래프 생성
sns.lmplot(x='x',y='y',data=anscombe,fit_reg=False,col='dataset',col_wrap=2)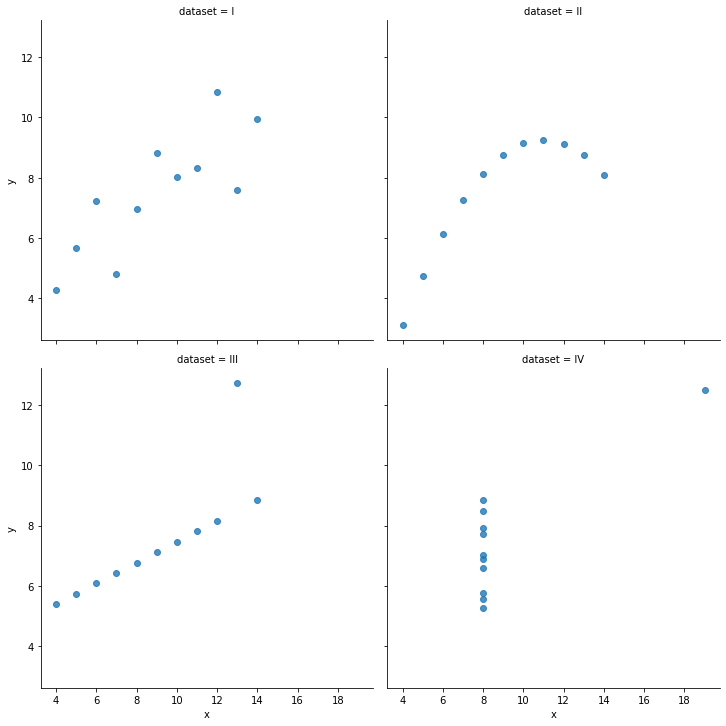
##col_wrap=2 옵션으로 그래프 2줄로 생성
#seaborn의 FacetGrid 클래스를 이용하여 그래프 그리기
facet=sns.FacetGrid(tips,col='time')
facet.map(sns.distplot,'total_bill',rug=True)

##map메서드를 통해 그래프 유형과 수치로 나타내고 싶은 데이터 설정 및 옵션 추가
facet=sns.FacetGrid(tips,col='day')
facet=facet.map(plt.scatter,'total_bill','tip') #x축,y축
facet=facet.add_legend()
##add_legend()는 그래프에 범례를 추가
##col='day'를 통해 day별로 나누고 map을 통해 그래프형태는 산점도,x축은 total_bill, y축은 tip으로 설정
##add_legend()로 범례 추가
facet=sns.FacetGrid(tips,col='day',hue='sex')
facet=facet.map(plt.scatter,'total_bill','tip') #x축,y축
facet=facet.add_legend() #범례(그래프 옆에 sex,male,female)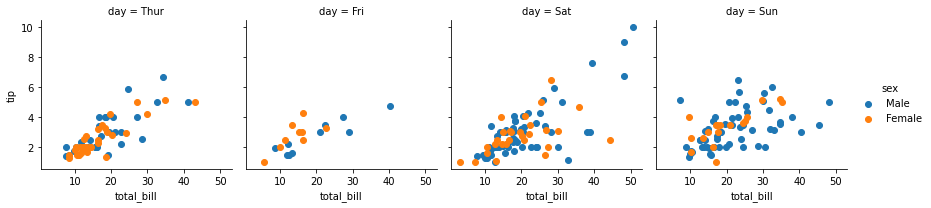
sns.lmplot(x='total_bill',y='tip',data=tips,hue='sex',fit_reg=False)
facet=sns.FacetGrid(tips,col='time',hue='sex')
facet.map(plt.scatter,'total_bill','tip')
facet=sns.FacetGrid(tips,col='time',hue='sex',row='smoker')
facet.map(plt.scatter,'total_bill','tip')
sns.set_style('whitegrid')
facet=sns.FacetGrid(tips,col='time',hue='sex',row='smoker')
facet.map(plt.scatter,'total_bill','tip')
##set_style('whitegrid') 은 그래프에 격자 추가
##row='smoker' ,col='time' 로 데이터의 행은 smoker ,열은 time 으로 구분
#데이터 합치기
##데이터 저장하고 각 데이터 조회하기
import pandas as pd
df1=pd.read_csv("concat_1.csv") #변수에 데이터 저장
df2=pd.read_csv("concat_2.csv")
df3=pd.read_csv("concat_3.csv")df1 #데이터 조회
df2
df3
##같은 열이름을 기준으로 데이터 합치기
pd.concat([df1,df2,df3])

##인덱스 새로 붙이기
pd.concat([df1,df2,df3],ignore_index=True)

##axis 옵션으로 표 형태 가로로 바꾸기(0==세로, 1==가로)
pd.concat([df1,df2,df3],axis=1) #axis=0이면 세로 axis=1이면 가로

##인텍스 새로 붙이기
pd.concat([df1,df2,df3],axis=1,ignore_index=True)
##문자열이였던 인덱스도 숫자로 새로 매겨짐.
#데이터 열이름 바꾸기
##데이터 조회하기
df1
##데이터 열이름 조회하기
>df1.columns
Index(['A', 'B', 'C', 'D'], dtype='object')
##데이터 열이름 바꾸기
df1.columns=['B','D','F','G']
df1
>>>데이터를 합칠 때 같은 열이름 기준으로 합쳤는데 열이름을 바꾼 후에는 데이터를 합치는 것이 가능할까??
가능은 하지만 없는 데이터는 Nan값으로 채운다.
#열이름이 다른 데이터 합치기
pd.concat([df1,df2,df3]) #붙여주긴하는데 Nan값으로 채운다
#행 이름 바꾸끼
df1.index=['1회차','2회차','3회차','4회차'] #행의 이름 바꾸기
df1
#서로 다른 데이터 합치기
person=pd.read_csv("survey_person.csv") #데이터 저장
site=pd.read_csv("survey_site.csv")
survey=pd.read_csv("survey_survey.csv")
visited=pd.read_csv("survey_visited.csv")person
site
survey
visited
##site와 visited 데이터프레임을 합치는데 site의 name열이랑 visited의 site열을 비교해가며 합치기
site.merge(visited,left_on='name',right_on='site')